
In our data-centric age, information is currency and web scraping stands as a formidable means of acquiring valuable data from the web. This blog post is your ticket to understanding the intricacies of web scraping, with a specific focus on extracting insights from Google. We’ll explore how to scrape Google related searches, and Google autocomplete suggestions data using the Python programming language. It’s important to be aware that web scraping Google search results may raise ethical and legal considerations, potentially conflicting with Google’s terms of service. Therefore, this tutorial is offered solely for educational purposes, equipping you with knowledge about web scraping techniques and their ethical implications.
Prerequisites: Before we dive into the world of web scraping, you’ll need a few tools and prerequisites:
- A working Python environment (Python 3 recommended)
- Required Python libraries: requests, BeautifulSoup, pandas
- An active internet connection
Setting Up the Environment: Setting up your Python environment is the first step in this journey. Follow these simple steps:
- Install Python (if not already installed).
- Create a virtual environment (recommended).
- Install the required libraries using pip.
# Example: Creating a virtual environment
# Open your command prompt or terminal and run the following commands:
# Create a virtual environment named 'web_scraping_env'
python -m venv web_scraping_env
# Activate the virtual environment
# On Windows
web_scraping_env\Scripts\activate
# On macOS and Linux
source web_scraping_env/bin/activate
# Install the required libraries using pip
pip install requests beautifulsoup4 pandas
Understanding the Code: Let’s start by breaking down the Python code that powers our web scraping adventure. We’ll walk you through the purpose of each function and its role in the code.
# Example: Function to retrieve data from Google suggest
def suggest(key):
r = requests.get(f'http://suggestqueries.google.com/complete/search?output=toolbar&hl=en&gl=in&q={key}')
soup = BeautifulSoup(r.content, 'lxml') # Use 'lxml' parser
sugg = [sugg['data'] for sugg in soup.find_all('suggestion')]
return sugg
Retrieving Data from Google: In this section, I’ll explain how the code sends an HTTP GET request to Google’s search page for a specified keyword. You’ll also learn how BeautifulSoup is used to parse the HTML content of the search results page.
# Example: Sending an HTTP GET request to Google
response = requests.get(search_url)
# Parsing HTML content with BeautifulSoup
soup = BeautifulSoup(response.text, 'lxml')
Extracting Related Searches: The “Related Searches” section of Google can provide valuable insights. We’ll guide you through the code that extracts these related searches, providing code snippets and explanations for each step.
# Example: Extracting "Related Searches" using BeautifulSoup
busquedasRelacionadas = soup.select('.Q71vJc')
if busquedasRelacionadas:
related_searches = [search.text.strip().lower() for search in busquedasRelacionadas]
Extracting Google Autocomplete Suggesttion: Discover how the code retrieves Google Autocomplete Suggestion data, uncovering its usefulness and applications. I’ll include examples of “Google Suggest” data to illustrate its potential.
# Example: Extracting "Google Suggest" data
google_suggest = suggest(keyword)
Exporting Data to Excel: Pandas, a powerful Python library, helps us create and manipulate DataFrames. Find out how the data is structured within the DataFrame and learn how the code exports this data to an Excel file.
# Example: Exporting data to an Excel file with pandas
df.to_excel('google_data_india.xlsx', index=False)
Generating Additional Data: To enhance your web scraping skills, we’ll explain how the code generates additional “Related Searches” and “Google Suggest” data for each suggestion. We’ll emphasize the importance of adding a delay to avoid IP blocking.
# Example: Generating additional related searches and Google suggest for each suggestion
for suggestion in google_suggest:
print(f"\nGenerating related searches and suggest for: {suggestion}")
time.sleep(5) # Delay for 5 seconds to avoid IP blocking
related_searches, google_suggest = get_related_searches_and_suggest(suggestion)
max_length = max(len(related_searches), len(google_suggest))
# Pad the shorter lists with empty strings
related_searches += [''] * (max_length - len(related_searches))
google_suggest += [''] * (max_length - len(google_suggest))
# Create a new DataFrame for the additional data
new_data = {'Initial Keyword': [suggestion] * max_length, 'Related Searches': related_searches, 'Google Suggest': google_suggest}
# Concatenate the new DataFrame with the existing one
df = pd.concat([df, pd.DataFrame(new_data)], ignore_index=True)
Executing the Code: Ready to get your hands dirty? Follow our step-by-step instructions for running the Python script, including code snippets for each step. Discover how to customize the keyword and output file name to suit your needs.
# Example: Executing the code
if __name__ == "__main__":
keyword = input("Enter the initial keyword to search for: ")
related_searches, google_suggest = get_related_searches_and_suggest(keyword)
max_length = max(len(related_searches), len(google_suggest))
# Pad the shorter lists with empty strings
related_searches += [''] * (max_length - len(related_searches))
google_suggest += [''] * (max_length - len(google_suggest))
data = {'Initial Keyword': [keyword] * max_length, 'Related Searches': related_searches, 'Google Suggest': google_suggest}
# Create a DataFrame from the data
df = pd.DataFrame(data)
# Export the DataFrame to an Excel file
df.to_excel('google_data_india.xlsx', index=False)
print("Data exported to 'google_data_india.xlsx'")
Complete Code:
import requests
from bs4 import BeautifulSoup
from googlesearch import search
import pandas as pd
import time
def get_related_searches_and_suggest(keyword, num_results=10):
# Prepare the Google search URL with the "gl" parameter set to "in" for India
search_url = f"https://www.google.com/search?q={keyword}&gl=in"
# Send an HTTP GET request to the Google search URL
response = requests.get(search_url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'lxml') # Use 'lxml' parser
# Extract "Related searches" section using provided code
related_searches = []
busquedasRelacionadas = soup.select('.Q71vJc')
if busquedasRelacionadas:
related_searches = [search.text.strip().lower() for search in busquedasRelacionadas]
# Extract "Google suggest" section
google_suggest = suggest(keyword)
return related_searches, google_suggest
else:
print("Failed to retrieve information.")
return [], []
# function to retrieve data from google suggest
def suggest(key):
r = requests.get(f'http://suggestqueries.google.com/complete/search?output=toolbar&hl=en&gl=in&q={key}')
soup = BeautifulSoup(r.content, 'lxml') # Use 'lxml' parser
sugg = [sugg['data'] for sugg in soup.find_all('suggestion')]
return sugg
if __name__ == "__main__":
keyword = input("Enter the initial keyword to search for: ")
related_searches, google_suggest = get_related_searches_and_suggest(keyword)
max_length = max(len(related_searches), len(google_suggest))
# Pad the shorter lists with empty strings
related_searches += [''] * (max_length - len(related_searches))
google_suggest += [''] * (max_length - len(google_suggest))
data = {'Initial Keyword': [keyword] * max_length, 'Related Searches': related_searches, 'Google Suggest': google_suggest}
# Create a DataFrame from the data
df = pd.DataFrame(data)
# Export the DataFrame to an Excel file
df.to_excel('google_data_india.xlsx', index=False)
print("Data exported to 'google_data_india.xlsx'")
# Generate additional related searches and Google suggest for each suggestion
for suggestion in google_suggest:
print(f"\nGenerating related searches and suggest for: {suggestion}")
time.sleep(5) # Delay for 5 seconds to avoid IP blocking
related_searches, google_suggest = get_related_searches_and_suggest(suggestion)
max_length = max(len(related_searches), len(google_suggest))
# Pad the shorter lists with empty strings
related_searches += [''] * (max_length - len(related_searches))
google_suggest += [''] * (max_length - len(google_suggest))
# Create a new DataFrame for the additional data
new_data = {'Initial Keyword': [suggestion] * max_length, 'Related Searches': related_searches, 'Google Suggest': google_suggest}
# Concatenate the new DataFrame with the existing one
df = pd.concat([df, pd.DataFrame(new_data)], ignore_index=True)
# Export the updated DataFrame to the same Excel file
df.to_excel('google_data_india.xlsx', index=False)
print("Updated data exported to 'google_data_india.xlsx'")
Code in action:
Looking for related searches and autocomplete suggestions for “white sneaker shoes”
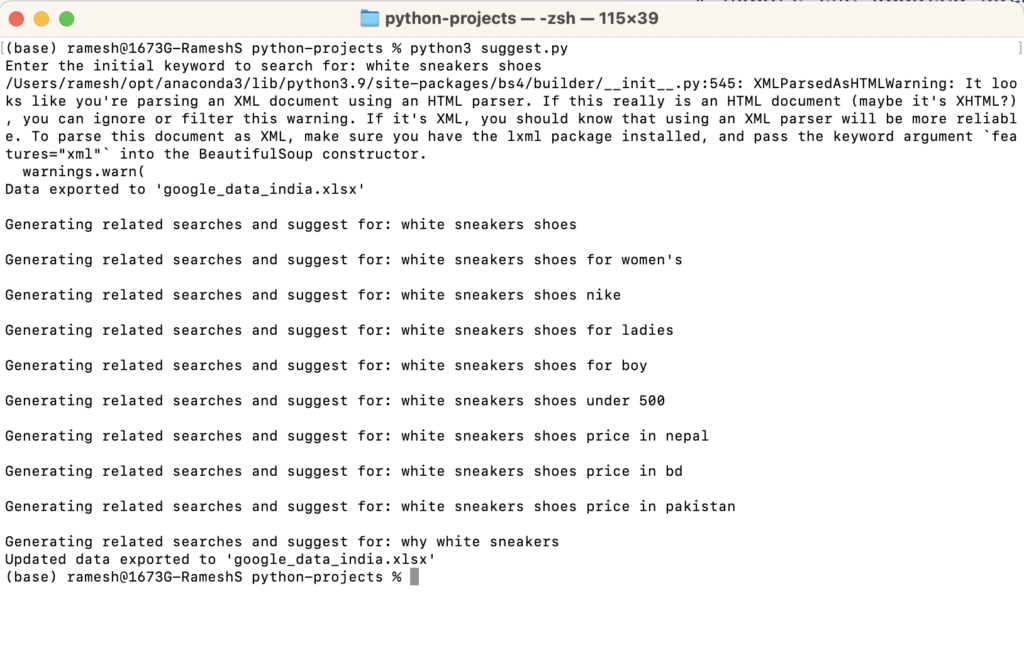
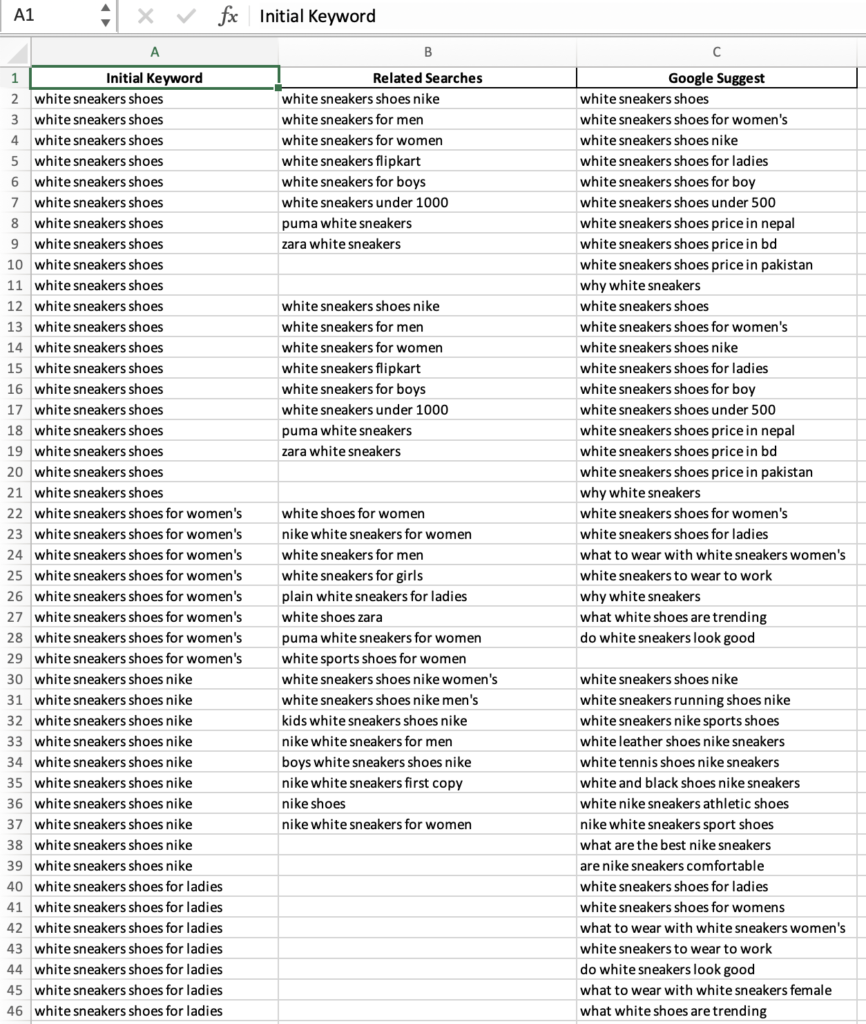
Exported data in Excel format:
Conclusion: In summary, web scraping is a powerful technique for extracting valuable data from the web. We’ve walked you through the process of scraping Google search results, related searches, and Google suggest data. However, it’s essential to tread carefully and respect website terms and policies. Always seek permission when scraping websites for non-educational or commercial purposes.
Disclaimer:Note: Web scraping Google search results may violate Google’s terms of service. This blog post is intended solely for educational purposes to help you understand web scraping techniques. It is essential to respect website terms and policies and seek permission when scraping websites for commercial or non-educational purposes.